向量存储(vector store)
- 前往Integrations,了解LangChain官方支持的所有第三方向量存储引擎。
存储和搜索非结构化数据最常见的方案是将数据的特征向量计算出来,然后在查询时通过向量相识度搜索,查询相似的向量。向量数据库就是负责提供向量存储和查询的数据存储引擎。
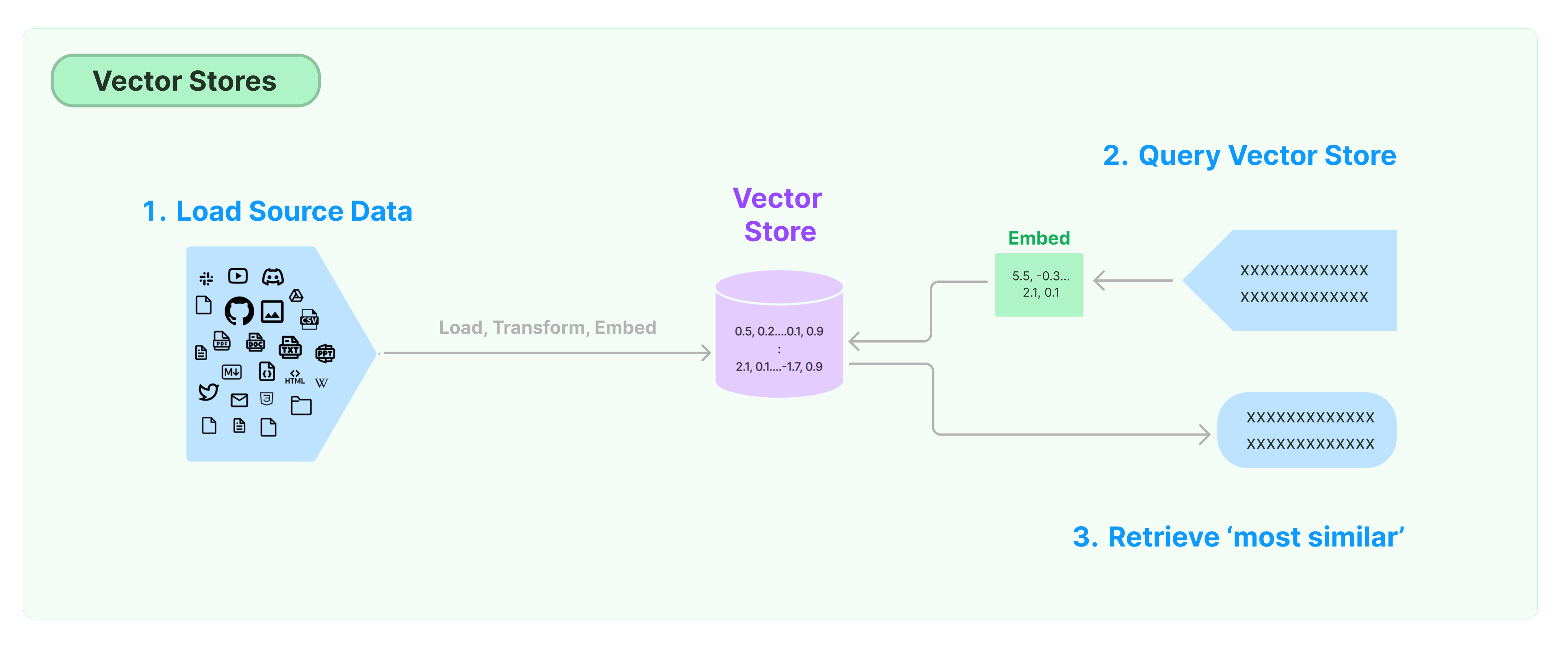
LangChain向量存储入门
本指南介绍了与VectorStores相关的基本功能。与向量存储一起工作的关键组件就是嵌入模型(负责计算特征向量)。因此,在学习本章之前,建议先学习文本嵌入模型如何计算文本向量。
有许多优秀的向量存储引擎,下面介绍3个免费开源的向量存储引擎在LangChain框架的用法。
Chroma
本章节使用chroma向量数据库,该数据库以python库的方式在本地运行。
pip install chromadb
这里使用OpenAI的嵌入模型计算向量,所以我们需要获取OpenAI API密钥。
import os
import getpass
# 配置openai key
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
# 加载原始文档,切割文档,然后将文档片段分别计算特征向量,然后把向量和关联的文本信息存储到向量数据库
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
FAISS
本章节使用FAISS向量数据库,它利用Facebook AI Similarity Search (FAISS)库。
pip install faiss-cpu
这里使用OpenAI的嵌入模型计算向量,所以我们需要获取OpenAI API密钥。
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
# 加载原始文档,切割文档,然后将文档片段分别计算特征向量,然后把向量和关联的文本信息存储到向量数据库
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = FAISS.from_documents(documents, OpenAIEmbeddings())
Lance
本章节,介绍LangChain框架如何使用LanceDB向量数据库。
pip install lancedb
这里使用OpenAI的嵌入模型计算向量,所以我们需要获取OpenAI API密钥。
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import LanceDB
import lancedb
# 初始化数据库,指定数据库文件
db = lancedb.connect("/tmp/lancedb")
table = db.create_table(
"my_table",
data=[
{
"vector": embeddings.embed_query("Hello World"),
"text": "Hello World",
"id": "1",
}
],
mode="overwrite",
)
# 加载原始文档,切割文档,然后将文档片段分别计算特征向量,然后把向量和关联的文本信息存储到向量数据库
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = LanceDB.from_documents(documents, OpenAIEmbeddings(), connection=table)
相似度搜索
query =“总统对Ketanji Brown Jackson说了什么?”
docs = db.similarity_search(query)
# 打印搜索结果
print(docs[0].page_content)
向量相似度搜索
使用 similarity_search_by_vector 根据给定的向量进行相似度搜索,该函数接受一个嵌入向量作为参数,而不是字符串。
embedding_vector = OpenAIEmbeddings().embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
# 这里查询的结果跟前面相同
print(docs[0].page_content)
异步操作
向量存储通常作为一个独立的服务运行,需要一些IO操作,因此使用异步调用向量数据库的接口。这样可以提高性能,因为你不必浪费时间等待外部服务的响应。
Langchain支持向量存储的异步操作。所有的方法都可以使用它们的异步函数来调用,前缀为a,表示async。
Qdrant是一个向量存储,支持所有异步操作,下面以Qdrant为例介绍。
pip install qdrant-client
from langchain_community.vectorstores import Qdrant
异步创建向量存储
db = await Qdrant.afrom_documents(documents, embeddings, "http://localhost:6333")
相似搜索
query =“总统对Ketanji Brown Jackson说了什么?”
docs = await db.asimilarity_search(query)
# 打印结果跟前面教程一样
print(docs[0].page_content)
根据向量搜索
embedding_vector = embeddings.embed_query(query)
docs = await db.asimilarity_search_by_vector(embedding_vector)
最大边际相关性搜索(MMR)
最大边际相关性优化了与查询的相似性以及所选文档之间的多样性。它也支持异步API。
query =“总统对Ketanji Brown Jackson说了什么?”
# 向量搜索的时候指定先查询10最相似的结果进行打分,最后返回最相似度最高的2个结果
found_docs = await qdrant.amax_marginal_relevance_search(query, k=2, fetch_k=10)
for i, doc in enumerate(found_docs):
print(f"{i + 1}.", doc.page_content, "\n")