Use case(使用案例)
企业数据通常存储在SQL数据库中。
使用LLMs可以通过自然语言与SQL数据库进行交互。
LangChain提供了SQL Chains和Agents来构建和运行基于自然语言提示的SQL查询。
这些与SQLAlchemy支持的任何SQL方言兼容(例如MySQL,PostgreSQL,Oracle SQL,Databricks,SQLite)。
它们可以用于以下用例:
- 根据自然语言问题生成要运行的查询
- 创建能够基于数据库数据回答问题的聊天机器人
- 基于用户想要分析的见解构建自定义仪表板
概述(Overview)
LangChain提供了与SQL数据库交互的工具:
- 基于自然语言用户问题构建SQL查询
- 使用链来查询SQL数据库进行查询创建和执行
- 使用代理与SQL数据库进行稳健和灵活的查询交互
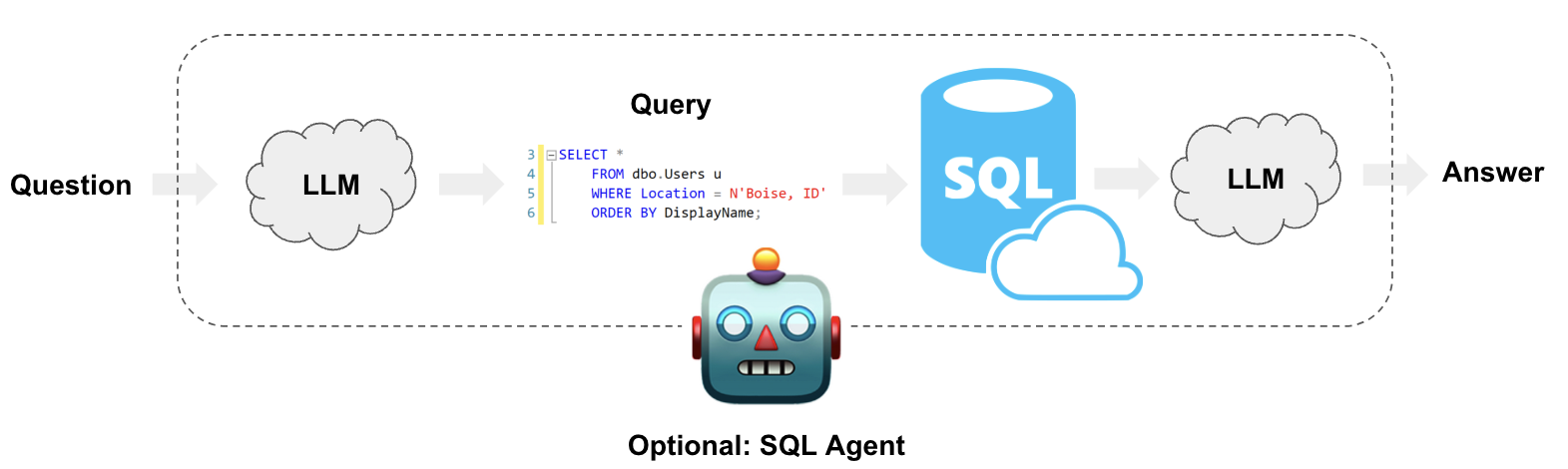
快速开始(Quickstart)
首先,获取所需的软件包并设置环境变量:
pip install langchain langchain-experimental openai
下面的示例将使用具有Chinook数据库的SQLite连接。
按照安装步骤在与本笔记本相同的目录中创建Chinook.db:
- 将此文件保存到
Chinook_Sqlite.sql目录中 - 运行
sqlite3 Chinook.db - 运行
.read Chinook_Sqlite.sql - 测试
SELECT * FROM Artist LIMIT 10;
现在,Chinhook.db在我们的目录中。
让我们创建一个SQLDatabaseChain来创建和执行SQL查询。
from langchain.utilities import SQLDatabase
from langchain.llms import OpenAI
from langchain_experimental.sql import SQLDatabaseChain
db = SQLDatabase.from_uri("sqlite:///Chinook.db")
llm = OpenAI(temperature=0, verbose=True)
db_chain = SQLDatabaseChain.from_llm(llm, db, verbose=True)
API参考(API Reference):
db_chain.run("有多少员工?")
> 进入新的SQLDatabaseChain链...
有多少员工?
SQL查询:SELECT COUNT(*) FROM "Employee";
SQL结果: [(8,)]
答案:一共有8名员工。
>链结束。
'一共有8名员工。'
请注意,这既创建了查询,也执行了查询。
在接下来的章节中,我们将介绍概述中提到的3种不同的使用案例。
深入(Go deeper)
您可以从SQL数据库以外的其他来源加载表格数据。例如:
- 加载CSV文件
- 加载Pandas DataFrame。在这里,您可以查看完整的文档加载器列表
案例1:文本到SQL查询(Case 1: Text-to-SQL query)
from langchain.chat_models import ChatOpenAI
from langchain.chains import create_sql_query_chain
API参考(API Reference):
让我们创建将构建SQL查询的链:
chain = create_sql_query_chain(ChatOpenAI(temperature=0), db)
response = chain.invoke({"question":"有多少员工"})
print(response)
SELECT COUNT(*) FROM Employee
根据用户问题构建SQL查询后,我们可以执行查询:
db.run(response)
'[(8,)]'
正如我们所见,SQL查询构建器链只是创建了查询,而我们将查询执行分开处理。
深入了解
深入了解内部运作
我们可以查看LangSmith跟踪来解析这个问题:
一些论文报道了以下提示的良好性能:
- 每个表的
CREATE TABLE描述,包括列名、列类型等信息 - 随后是在
SELECT语句中的三个示例行
create_sql_query_chain采用了这个最佳实践(在此博客中可了解更多)。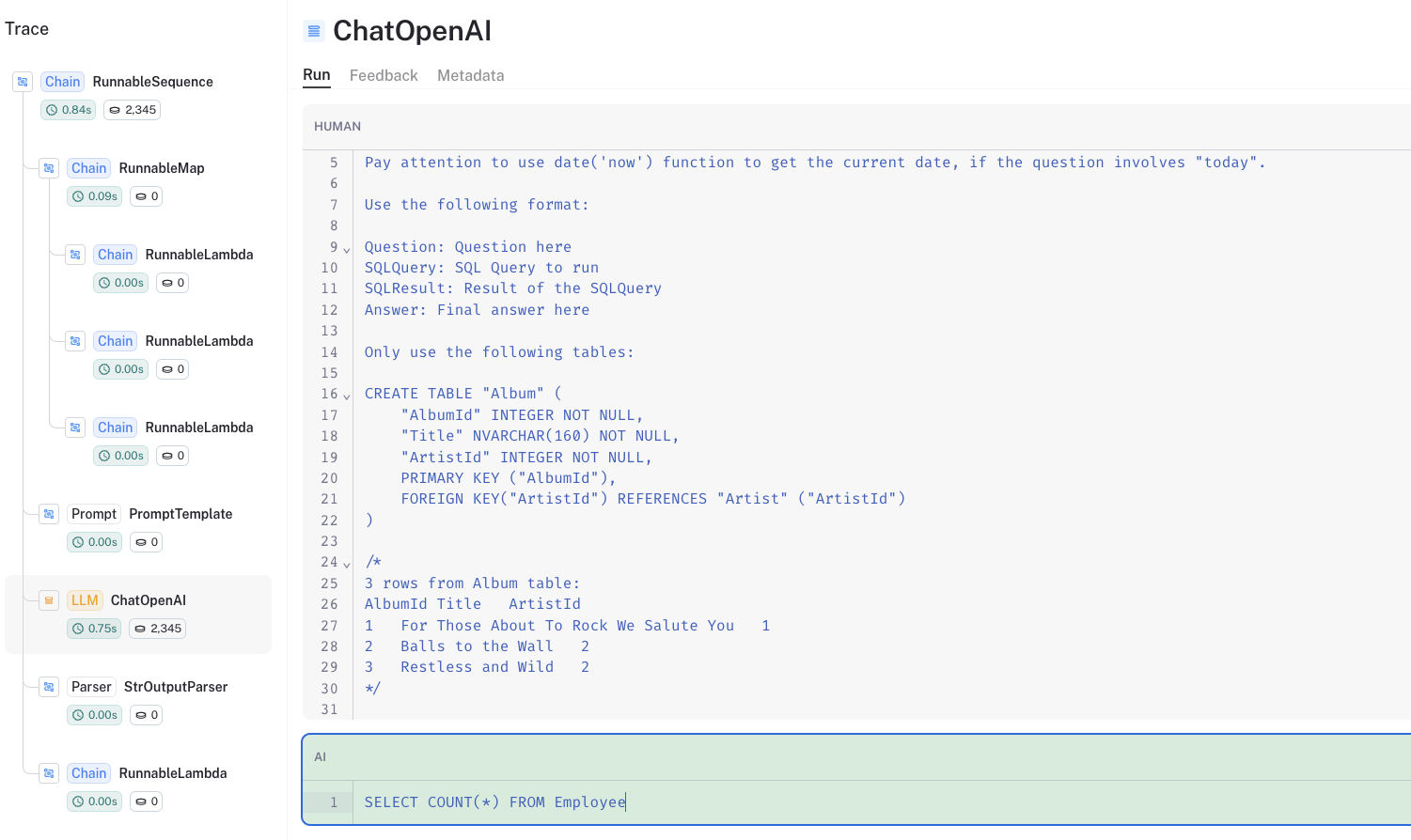
改进方法
查询生成器可以通过多种方式改进,例如(但不限于):
- 根据特定的用例自定义数据库描述
- 在提示中硬编码一些问题及其相应的SQL查询示例
- 使用向量数据库来包含与具体用户问题相关的动态示例
所有这些示例都涉及自定义的链式提示。
例如,我们可以在提示中包含一些示例,如下所示:
from langchain.prompts import PromptTemplate
TEMPLATE = """给定一个输入问题,首先创建一个语法正确的{dialect}查询以运行,然后查看查询结果并返回答案。
使用以下格式:
问题:"问题在这里"
SQL查询:"要运行的SQL查询"
SQL结果:"SQL查询的结果"
答案:"最终答案在这里"
仅使用以下表:
{table_info}。
一些对应于问题的SQL查询示例包括:
{few_shot_examples}
问题:{input}"""
CUSTOM_PROMPT = PromptTemplate(
input_variables=["input", "few_shot_examples", "table_info", "dialect"], template=TEMPLATE
)
API 参考:
我们还可以在LangChain提示中心访问这个prompt。
这将与您的LangSmith API密钥一起使用。
from langchain import hub
CUSTOM_PROMPT = hub.pull("rlm/text-to-sql")
案例二:文本转SQL查询和执行
我们可以使用langchain_experimental中的SQLDatabaseChain来创建和运行SQL查询。
from langchain.llms import OpenAI
from langchain_experimental.sql import SQLDatabaseChain
llm = OpenAI(temperature=0, verbose=True)
db_chain = SQLDatabaseChain.from_llm(llm, db, verbose=True)
API 参考:
db_chain.run("有多少员工?")
> 进入新的SQLDatabaseChain链...
有多少员工?
SQL查询:SELECT COUNT(*) FROM "Employee";
SQL结果:[(8,)]
答案:有8名员工。
> 完成链条。
'有8名员工。'
正如我们所看到的,我们得到了与前一个案例相同的结果。
在这里,链条还处理了查询执行,根据用户的问题和查询结果提供了最终的答案。
使用此方法时要小心,因为它容易受到SQL注入的影响:
- 链条执行了由LLM创建的、未经验证的查询
- 例如,记录可能会被无意中创建、修改或删除
这就是我们看到SQLDatabaseChain位于langchain_experimental中的原因。
深入了解
查看源码
我们可以使用LangSmith trace来查看内部是如何工作的:
- 如上所述,首先我们创建查询:
text: ' SELECT COUNT(*) FROM "Employee";'
- 然后,执行查询并将结果传递给LLM进行综合处理。
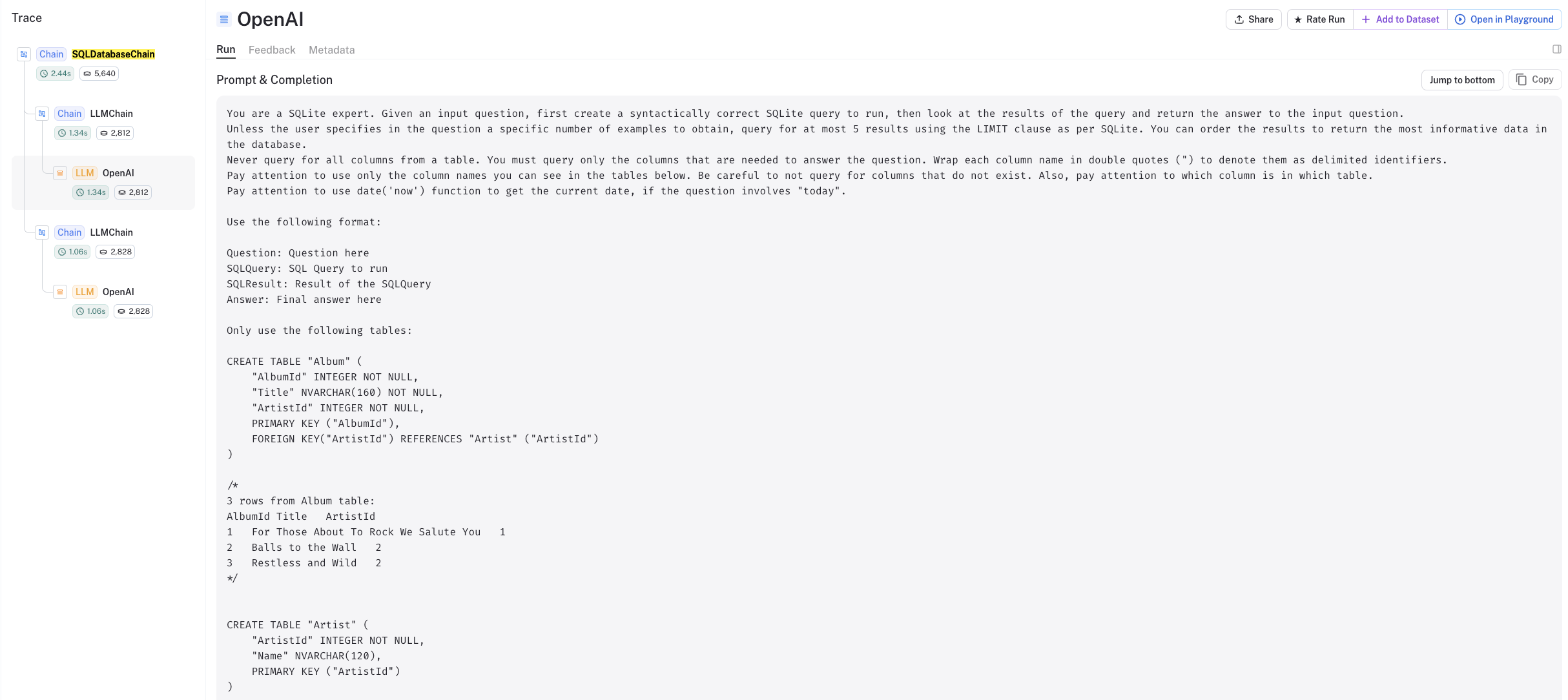
改进
SQLDatabaseChain的性能可以通过以下几种方式进行改进:
- 添加样本行
- 指定自定义表信息
- 使用查询检查器
use_query_checker=True来纠正无效的SQL语句 - 使用自定义的LLM Prompt,包括特定的说明或相关信息,使用参数
prompt=CUSTOM_PROMPT - 使用参数
return_intermediate_steps=True获取SQL语句的中间步骤以及最终结果 - 使用参数
top_k=5限制查询返回的行数
当数据库中的表的数量较大时,您可能会发现 SQLDatabaseSequentialChain 很有用。
该 Sequential Chain的处理过程如下:
- 根据用户的问题确定要使用的表
- 只使用相关表调用正常的SQL数据库链
添加样本行
在数据格式不明显时,提供样本数据可以帮助LLM构建正确的查询。
例如,我们可以通过从Track表中提供两行来告诉LLM艺术家是以全名保存的。
db = SQLDatabase.from_uri(
"sqlite:///Chinook.db",
include_tables=['Track'], # 我们只包含一个表来保存提示中的标记 :)
sample_rows_in_table_info=2)
样本行将添加到每个对应表的列信息后面。
我们可以使用 db.table_info 并检查包含了哪些样本行:
print(db.table_info)
CREATE TABLE "Track" (
"TrackId" INTEGER NOT NULL,
"Name" NVARCHAR(200) NOT NULL,
"AlbumId" INTEGER,
"MediaTypeId" INTEGER NOT NULL,
"GenreId" INTEGER,
"Composer" NVARCHAR(220),
"Milliseconds" INTEGER NOT NULL,
"Bytes" INTEGER,
"UnitPrice" NUMERIC(10, 2) NOT NULL,
PRIMARY KEY ("TrackId"),
FOREIGN KEY("MediaTypeId") REFERENCES "MediaType" ("MediaTypeId"),
FOREIGN KEY("GenreId") REFERENCES "Genre" ("GenreId"),
FOREIGN KEY("AlbumId") REFERENCES "Album" ("AlbumId")
)
/*
2 rows from Track table:
TrackId Name AlbumId MediaTypeId GenreId Composer Milliseconds Bytes UnitPrice
1 For Those About To Rock (We Salute You) 1 1 1 Angus Young, Malcolm Young, Brian Johnson 343719 11170334 0.99
2 Balls to the Wall 2 2 1 None 342562 5510424 0.99
*/
案例3:SQL代理
LangChain拥有一种称为SQL代理的工具,它能够比SQLDatabaseChain更灵活地与SQL数据库进行交互。
使用SQL代理的主要优点包括:
- 它可以根据数据库模式以及数据库内容(例如描述特定表)回答问题。
- 它可以通过运行生成的查询、捕获回溯信息并重新正确生成来从错误中恢复。
要初始化代理,我们使用create_sql_agent函数。
该代理包含SQLDatabaseToolkit,其中包含以下工具:
- 创建和执行查询
- 检查查询语法
- 检索表描述
- …等等
from langchain.agents import create_sql_agent
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.agents.agent_types import AgentType
db = SQLDatabase.from_uri("sqlite:///Chinook.db")
llm = OpenAI(temperature=0, verbose=True)
agent_executor = create_sql_agent(
llm=OpenAI(temperature=0),
toolkit=SQLDatabaseToolkit(db=db, llm=OpenAI(temperature=0)),
verbose=True,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
)
API参考:
- create_sql_agent
- SQLDatabaseToolkit
- AgentExecutor
- AgentType
代理任务示例 #1 - 运行查询
agent_executor.run(
"列出每个国家的总销售额。哪个国家的客户花费最多?"
)
在这个示例中,我们使用agent_executor.run()函数来运行一个查询任务。任务是要求列出每个国家的总销售额,并查找花费最多的国家的客户。
> Entering new AgentExecutor chain...
Action: sql_db_list_tables
Action Input:
Observation: Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, Track
Thought: I should query the schema of the Invoice and Customer tables.
Action: sql_db_schema
Action Input: Invoice, Customer
Observation:
CREATE TABLE "Customer" (
"CustomerId" INTEGER NOT NULL,
"FirstName" NVARCHAR(40) NOT NULL,
"LastName" NVARCHAR(20) NOT NULL,
"Company" NVARCHAR(80),
"Address" NVARCHAR(70),
"City" NVARCHAR(40),
"State" NVARCHAR(40),
"Country" NVARCHAR(40),
"PostalCode" NVARCHAR(10),
"Phone" NVARCHAR(24),
"Fax" NVARCHAR(24),
"Email" NVARCHAR(60) NOT NULL,
"SupportRepId" INTEGER,
PRIMARY KEY ("CustomerId"),
FOREIGN KEY("SupportRepId") REFERENCES "Employee" ("EmployeeId")
)
/*
3 rows from Customer table:
CustomerId FirstName LastName Company Address City State Country PostalCode Phone Fax Email SupportRepId
1 Luís Gonçalves Embraer - Empresa Brasileira de Aeronáutica S.A. Av. Brigadeiro Faria Lima, 2170 São José dos Campos SP Brazil 12227-000 +55 (12) 3923-5555 +55 (12) 3923-5566 luisg@embraer.com.br 3
2 Leonie Köhler None Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 +49 0711 2842222 None leonekohler@surfeu.de 5
3 François Tremblay None 1498 rue Bélanger Montréal QC Canada H2G 1A7 +1 (514) 721-4711 None ftremblay@gmail.com 3
*/
CREATE TABLE "Invoice" (
"InvoiceId" INTEGER NOT NULL,
"CustomerId" INTEGER NOT NULL,
"InvoiceDate" DATETIME NOT NULL,
"BillingAddress" NVARCHAR(70),
"BillingCity" NVARCHAR(40),
"BillingState" NVARCHAR(40),
"BillingCountry" NVARCHAR(40),
"BillingPostalCode" NVARCHAR(10),
"Total" NUMERIC(10, 2) NOT NULL,
PRIMARY KEY ("InvoiceId"),
FOREIGN KEY("CustomerId") REFERENCES "Customer" ("CustomerId")
)
/*
3 rows from Invoice table:
InvoiceId CustomerId InvoiceDate BillingAddress BillingCity BillingState BillingCountry BillingPostalCode Total
1 2 2009-01-01 00:00:00 Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 1.98
2 4 2009-01-02 00:00:00 Ullevålsveien 14 Oslo None Norway 0171 3.96
3 8 2009-01-03 00:00:00 Grétrystraat 63 Brussels None Belgium 1000 5.94
*/
Thought: I should query the total sales per country.
Action: sql_db_query
Action Input: SELECT Country, SUM(Total) AS TotalSales FROM Invoice INNER JOIN Customer ON Invoice.CustomerId = Customer.CustomerId GROUP BY Country ORDER BY TotalSales DESC LIMIT 10
Observation: [('USA', 523.0600000000003), ('Canada', 303.9599999999999), ('France', 195.09999999999994), ('Brazil', 190.09999999999997), ('Germany', 156.48), ('United Kingdom', 112.85999999999999), ('Czech Republic', 90.24000000000001), ('Portugal', 77.23999999999998), ('India', 75.25999999999999), ('Chile', 46.62)]
Thought: I now know the final answer
Final Answer: The country with the highest total sales is the USA, with a total of $523.06.
> Finished chain.
'The country with the highest total sales is the USA, with a total of $523.06.'
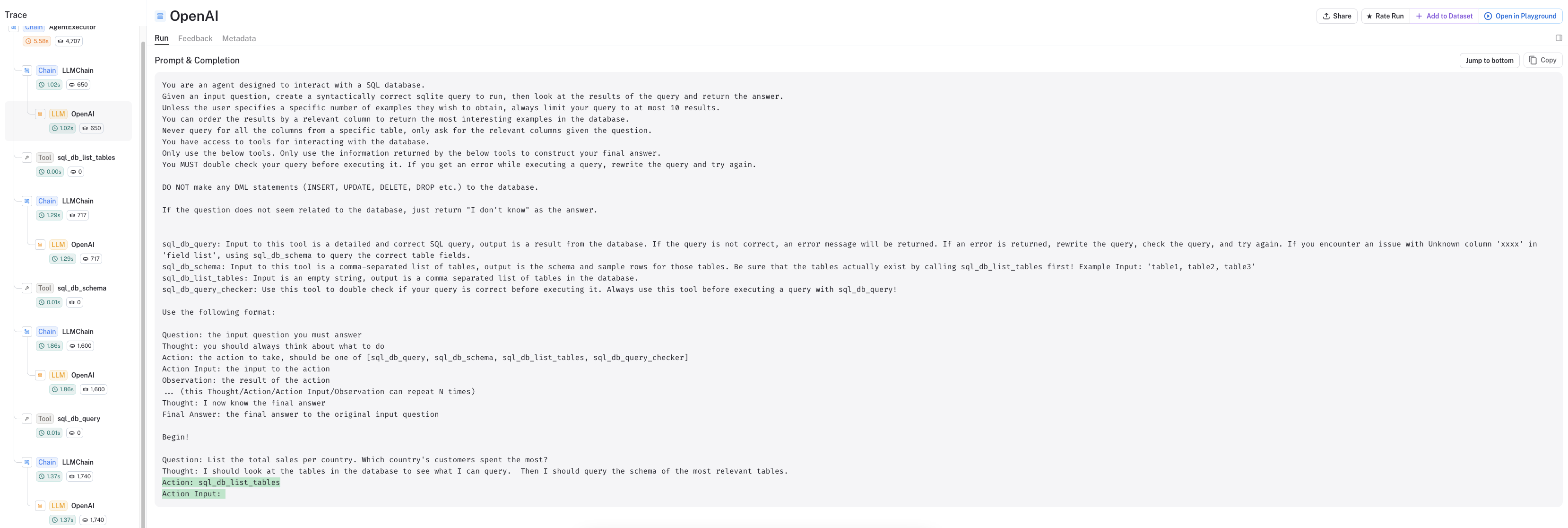
查看LangSmith跟踪,我们可以看到:
- 代理正在使用ReAct样式的提示
- 首先,它将查看这些表:
Action: sql_db_list_tables,使用工具sql_db_list_tables - 给定这些表作为观察结果,它会“思考”,然后确定下一个“动作”:
观察结果:Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, Track
思考:我应该查询Invoice和Customer表的模式。
动作:sql_db_schema
动作输入:Invoice, Customer
- 然后,它使用来自工具
sql_db_schema的模式构建查询
思考:我应该按国家查询总销售额。
动作:sql_db_query
动作输入:SELECT Country, SUM(Total) AS TotalSales FROM Invoice INNER JOIN Customer ON Invoice.CustomerId = Customer.CustomerId GROUP BY Country ORDER BY TotalSales DESC LIMIT 10
- 最后,它使用工具
sql_db_query执行生成的查询
代理任务示例 #2 - 描述一个表格
agent_executor.run("描述 playlisttrack 表格")
> 进入新的 AgentExecutor 链...
动作:sql_db_list_tables
动作输入:
观察结果:Album、Artist、Customer、Employee、Genre、Invoice、InvoiceLine、MediaType、Playlist、PlaylistTrack、Track
思考结果:PlaylistTrack 表格是最相关的。
动作:sql_db_schema
动作输入:PlaylistTrack
观察结果:
CREATE TABLE "PlaylistTrack" (
"PlaylistId" INTEGER NOT NULL,
"TrackId" INTEGER NOT NULL,
PRIMARY KEY ("PlaylistId", "TrackId"),
FOREIGN KEY("TrackId") REFERENCES "Track" ("TrackId"),
FOREIGN KEY("PlaylistId") REFERENCES "Playlist" ("PlaylistId")
)
/*
PlaylistTrack 表格的 3 行:
PlaylistId TrackId
1 3402
1 3389
1 3390
*/
思考结果:我现在知道最终答案了
最终答案:PlaylistTrack 表格包含两个列:PlaylistId 和 TrackId,它们都是整数类型,并且形成一个主键。它还有两个外键,一个指向 Track 表格,一个指向 Playlist 表格。
> 链结束。
'PlaylistTrack 表格包含两个列:PlaylistId 和 TrackId,它们都是整数类型,并且形成一个主键。它还有两个外键,一个指向 Track 表格,一个指向 Playlist 表格。'
进一步了解
要了解有关 SQL 代理的更多信息以及其工作原理,请参阅 SQL 代理工具包文档。
您还可以检查其他文档类型的代理:
- Pandas 代理
- CSV 代理
Elastic Search
在上面的用例之外,还可以与其他数据库集成。
例如,我们可以与 Elasticsearch 分析数据库进行交互。
这个链条通过 Elasticsearch DSL API(过滤器和汇总)构建搜索查询。
Elasticsearch 客户端必须具有进行索引列表、映射描述和搜索查询的权限。
有关如何在本地运行 Elasticsearch 的说明,请参阅 这里。
在安装 Elasticsearch Python 客户端之前,请确保:
pip install elasticsearch
from elasticsearch import Elasticsearch
from langchain.chat_models import ChatOpenAI
from langchain.chains.elasticsearch_database import ElasticsearchDatabaseChain
API 参考:
ELASTIC_SEARCH_SERVER = "https://elastic:pass@localhost:9200"
db = Elasticsearch(ELASTIC_SEARCH_SERVER)
取消注释下一个单元格以首次填充您的数据库。
llm = ChatOpenAI(model_name="gpt-4", temperature=0)
chain = ElasticsearchDatabaseChain.from_llm(llm=llm, database=db, verbose=True)
question = "所有客户的名字是什么?"
chain.run(question)
我们可以自定义提示。
from langchain.chains.elasticsearch_database.prompts import DEFAULT_DSL_TEMPLATE
from langchain.prompts.prompt import PromptTemplate
PROMPT_TEMPLATE = """给定一个输入问题,创建一个语法正确的 Elasticsearch 查询来执行。除非用户在问题中指定了他们希望获得的具体数量的示例,否则始终将查询限制在最多 {top_k} 个结果。您可以按照相关列对结果进行排序,以返回数据库中最有趣的示例。
除非告诉你不需要从特定索引中查询所有的列,只查询与问题相关的少数列即可。
注意使用只能在映射描述中看到的列名。注意不要查询不存在的列。另外,注意哪个列属于哪个索引。将查询返回为有效的 json。
使用以下格式:
问题:此处是问题
ESQuery: Elasticsearch 查询,格式化为 json
"""
PROMPT = PromptTemplate.from_template(
PROMPT_TEMPLATE,
)
chain = ElasticsearchDatabaseChain.from_llm(llm=llm, database=db, query_prompt=PROMPT)