索引(index)
Qdrant的一个关键特性是向量索引和传统索引的有效结合。这一点非常重要,因为为了使向量搜索在过滤条件下能够有效运行,仅有向量索引是不够的。简单来说,向量索引加速了向量搜索,而载荷(payload)索引加速了过滤。
段落中的索引是独立存在的,但是索引本身的参数是为整个集合配置的。
并不是所有的段落都自动具备索引。这取决于优化设置的需求,并且通常取决于存储的点数。
载荷索引
Qdrant中的载荷索引与传统面向文档数据库中的索引类似。该索引是为指定的字段和类型构建的,用于根据相应的过滤条件快速获取点。
该索引还用于准确估计筛选条件的基数,这有助于查询规划选择搜索策略。
创建索引需要额外的计算资源和内存,因此选择要索引的字段非常重要。Qdrant不会为您做出这个选择,而是将其授予用户。
要将字段标记为可索引,可以使用以下方法:
PUT /collections/{collection_name}/index
{
"field_name": "要索引的字段名称",
"field_schema": "关键字"
}
可用的字段类型有:
keyword- 用于关键字载荷,影响匹配过滤条件。integer- 用于整数载荷,影响匹配和范围过滤条件。float- 用于浮点数载荷,影响范围过滤条件。bool- 用于布尔载荷,影响匹配过滤条件(从版本1.4.0开始可用)。geo- 用于地理载荷,影响地理边界框和地理半径过滤条件。text- 一种特殊的索引类型,适用于关键字/字符串载荷,影响全文搜索过滤条件。
载荷索引可能占用一些额外的内存,因此建议仅对在筛选条件中使用的字段使用索引。如果您需要依据许多字段进行筛选,而内存限制不允许对它们全部进行索引,则建议选择限制搜索结果最多的字段。通常来说,一个载荷值拥有的不同值越多,索引的使用将更有效。
全文索引
从版本0.10.0开始可用
Qdrant支持对字符串载荷进行全文搜索。全文索引允许您通过载荷字段中的单词或词组的存在来过滤点。
全文索引的配置略微复杂,因为您可以指定标记化参数。标记化是将字符串分隔成标记的过程,然后将这些标记索引到反向索引中。
要创建一个全文索引,可以使用以下方法:
PUT /collections/{collection_name}/index
{
"field_name": "要索引的字段名称",
"field_schema": {
"type": "text",
"tokenizer": "word",
"min_token_len": 2,
"max_token_len": 20,
"lowercase": true
}
}
可用的标记化程序有:
word- 将字符串按照空格、标点符号和特殊字符进行分隔。whitespace- 将字符串按照空格进行分隔。prefix- 将字符串按照空格、标点符号和特殊字符进行分隔,然后为每个单词创建一个前缀索引。例如:hello将被索引为h,he,hel,hell,hello。multilingual- 基于charabia包的特殊类型的标记化程序。它允许对多种语言进行正确的标记化和词形还原,包括具有非拉丁字母和非空格分隔符的语言。请参阅charabia文档以获取支持的语言和归一化选项的完整列表。在默认构建配置中,qdrant不包含对所有语言的支持,因为这会导致二进制文件的大小增加。中文、日文和韩文在默认情况下是未启用的,但可以通过使用--features multiling-chinese,multiling-japanese,multiling-korean标志从源码构建qdrant来启用它们。
请参阅全文匹配示例以了解使用全文索引进行查询的示例。
向量索引
向量索引是基于向量的数据结构,通过特定的数学模型构建。通过向量索引,我们可以高效地查询与目标向量相似的多个向量。
Qdrant目前仅使用HNSW作为向量索引。
HNSW(Hierarchical Navigable Small World Graph)是一种基于图的索引算法。根据一定的规则,它为图像构建了多层导航结构。在这个结构中,上层更稀疏,节点之间的距离更远。下层更密集,节点之间的距离更近。搜索从最顶层开始,在该层中找到离目标最近的节点,然后进入下一层开始另一次搜索。经过多次迭代,可以快速接近目标位置。
为了提高性能,HNSW限制了图的每一层上节点的最大度数为m。此外,您可以使用ef_construct(构建索引时)或ef(搜索目标时)指定搜索范围。
这些参数可以在配置文件中配置:
storage:
hnsw_index:
m: 16
ef_construct: 100
full_scan_threshold: 10000
在创建集合的过程中,可以配置ef参数,并且默认情况下等于ef_construct。
HNSW之所以被选择,有几个原因。首先,HNSW与允许Qdrant在搜索过程中使用过滤器的修改非常兼容。其次,根据公共基准测试,它是最准确和最快的算法之一。
自v1.1.1起可用
HNSW参数还可以通过将hnsw_config设置为对集合和命名向量进行微调以优化搜索性能。
可过滤索引
单独的payload索引和向量索引不能完全解决使用过滤器进行搜索的问题。
在过滤器较弱的情况下,可以直接使用HNSW索引。在过滤器严格的情况下,可以使用payload索引并进行完全重新得分。然而,在中间情况下,这种方法效果不佳。
一方面,我们不能对太多的向量进行全扫描。另一方面,使用过于严格的过滤器时,HNSW图开始崩溃。
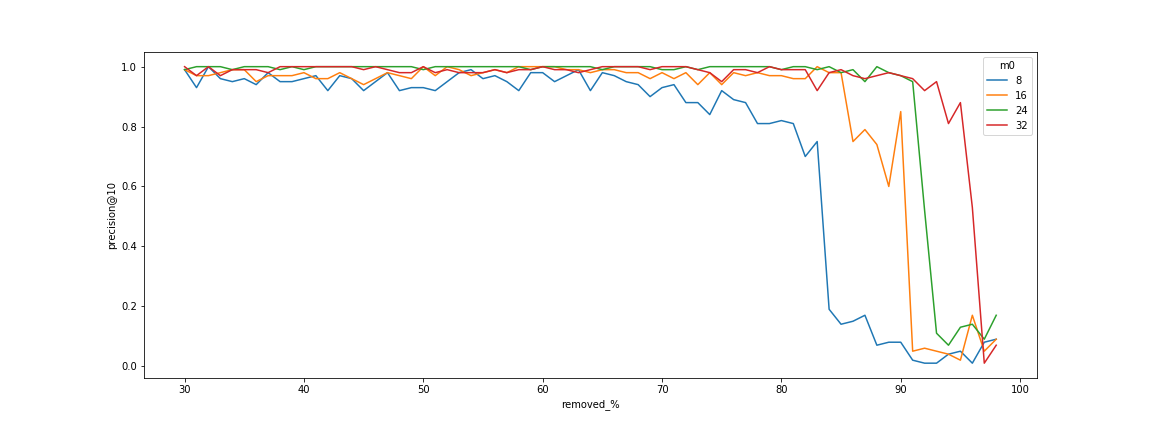

额外的边使得您可以使用HNSW索引高效地搜索附近的向量,并在图中搜索时应用过滤器。
这种方法最小化了条件检查的开销,因为您只需要对参与搜索的一小部分点计算条件。