检索
许多LLM应用程序需要用户特定数据,这些数据不是模型的训练集的一部分。通过检索增强生成(RAG)是实现这一目标的主要方式。在该过程中,外部数据被检索,然后在进行生成步骤时传递给LLM。
提示:LangChain检索组件是提供查询本地数据的主要工具,主要用于查询本地数据,然后丢给AI处理。
LangChain提供了从简单到复杂的RAG应用程序的所有构建块。本文档的这一部分涵盖了与检索步骤相关的一切,例如数据的提取。尽管听起来很简单,但实际上可能会有些微妙的复杂性。这涉及几个关键模块。
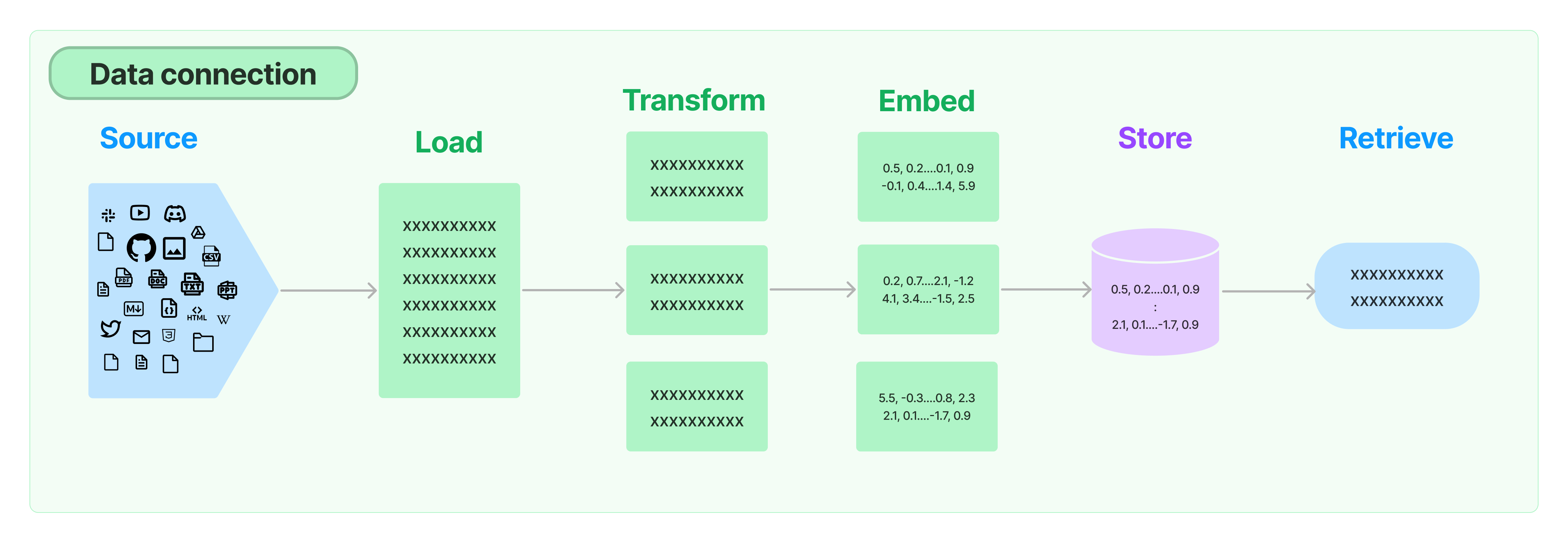
文档加载器
从许多不同来源加载文档。LangChain提供了许多不同的文档加载器以及与其他主要提供商(如Unstructured)的集成。我们提供了加载所有类型文档(html、PDF、代码)的集成,从所有类型的位置(私人s3 Bucket、公共网站)。
文档转换器
检索的一个重要部分是仅获取文档的相关部分。这涉及多个转换步骤,以最好地准备文档以进行检索。这里的一个主要步骤是将大文档分割(或切块)成较小的块。LangChain提供了几种不同的算法来完成这个任务,并针对特定文档类型(代码、markdown等)进行了优化。
文本嵌入模型
检索的另一个重要部分是为文档创建嵌入。嵌入捕捉文本的语义含义,允许您快速有效地查找其他相似的文本片段。LangChain提供与不同的嵌入提供商和方法的集成,从开源到专有API,让您选择最适合您需求的模型。LangChain提供了一个标准接口,方便您轻松切换模型。
向量存储器
随着嵌入的兴起,出现了对支持这些嵌入的数据库进行高效存储和搜索的需求。LangChain提供与许多不同的向量存储器的集成,从开源本地存储器到云托管专有存储器,让您选择最适合您需求的存储器。LangChain提供一个标准接口,方便您轻松切换向量存储器。
检索器
一旦数据在数据库中,您仍然需要检索它。LangChain支持许多不同的检索算法,并且在这方面我们增加了最多的价值。我们支持基本的、易于入门的方法,即简单的语义搜索。然而,我们还添加了一系列基于此的算法,以提高性能。这些算法包括:
- 父文档检索器:允许您为每个父文档创建多个嵌入,从而可以查找较小的块但返回较大的上下文。
- 自查询检索器:用户的问题通常包含对某个不仅仅是语义的事物的引用,而是表达出一些逻辑,该逻辑最好表示为元数据过滤器。自查询允许您从查询中解析出语义部分以及查询中存在的其他元数据过滤器。
- 当然,还有更多!