概念介绍
文本嵌入(Text Embedding)是自然语言处理中的一个重要概念,它的目标是将文本中的词表示成固定长度的稠密向量,也称为词向量(Word Vector)。这样每个词都可以用一个连续的、低维的稠密向量来表示,比如200-300维。
文本嵌入的主要目的是捕捉每个词的语义信息,使得语义相关的词在嵌入空间中距离较近,不相关的词距离较远。这样就可以用向量间的距离来表示词之间的语义关系。
例如:
参考下图向量在几何空间的表示,Girl(女孩)和Boy(男孩),queen(女王)和king(国王),Sport(运动)和game(游戏)这三对单词都有相近的语义关系,所以他们的文本向量的几何距离都比较近。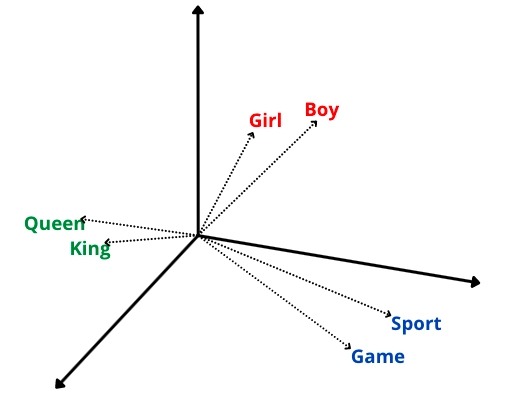
文本嵌入可以通过神经网络模型进行无监督学习得到,比如word2vec中的CBOW和SKIP-GRAM模型,以及GloVe等。这些模型通过大规模文本的统计信息来学习每个词的向量表示。
文本嵌入与文本向量
通过文本嵌入模型(embedding)可以计算出文本的特征向量,在文本嵌入中,每个词或短语都被赋予一个向量。这些向量可以组成文本的向量表示,从而表示整个文本的含义,也叫文本特征向量,因为这些向量可以表示文本的语义信息等关键特征信息。
文本嵌入模型计算出来的向量长度不同模型不一样,大致就是一个浮点数数组。
例如:
通过m3e嵌入模型计算下面这段文本的向量
Mixed 此文本嵌入模型支持中英双语的同质文本相似度计算,异质文本检索等功能,未来还会支持代码检索,ALL in one
会得到一个长度为768的浮点数数组。
[ 3.60721558e-01 7.86174655e-01 8.18841517e-01 -2.01314002e-01
-1.74384236e-01 -1.00326824e+00 -1.72811300e-01 -1.04662508e-01....省略...
]
应用场景
文本嵌入可以用于各种NLP任务,如下所示:
- 文本相似度搜索
- 文本分类任务
- 情感分析
- 垃圾邮件过滤
- 文本推荐
- 自动翻译
- 实体识别
- 问答系统
如上述应用场景,文本嵌入可以为机器提供更好的语义信息,从而提高自然语言处理的效果,同时也在搜索引擎、社交媒体分析、金融分析、医疗保健等领域得到了广泛应用。
常用的文本嵌入模型
以下是一些流行的文本嵌入模型:
- Word2Vec:一种基于神经网络的模型,用于生成单词的向量表示。
- GloVe:一种基于共现矩阵的模型,用于生成单词的向量表示。
- FastText:Facebook开发的一种基于字符级别的文本嵌入模型,可以为单词和短语生成向量表示。
- BERT:一种基于Transformer的语言模型,可以生成单词、短语甚至是整个句子的向量表示。
- M3E:Moka Massive Mixed Embedding的缩写
- OpenAI Embeddings:这是OpenAI官方发布的Embeddings的API接口,目前主要是text-embedding-ada-002模型
除了这些还有很多开源或者付费的嵌入模型。