Logstash同步数据,主要有三个核心环节:inputs → filters → outputs,流程如下图。
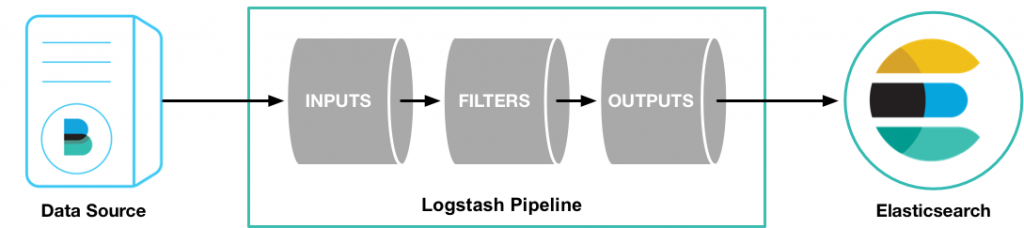
inputs模块负责收集数据,filters模块可以对收集到的数据进行格式化、过滤、简单的数据处理,outputs模块负责将数据同步到目的地,Logstash的处理流程,就像管道一样,数据从管道的一端,流向另外一端。
提示:inputs/filters/outputs是通过插件机制扩展各种能力。
inputs
inputs可以收集多种数据源的数据,下面是常见的数据源:
- file - 扫描磁盘中的文件数据,例如: 扫描日志文件。
- mysql - 扫描Mysql的表数据
- redis
- Filebeat - 轻量级的文件数据采集器,可以取代file的能力。
- 消息队列kafka、rabbitmq等 - 支持从各种消息队列读取数据。
filters
filters是一个可选模块,可以在数据同步到目的地之前,对数据进行一些格式化、过滤、简单的数据处理操作。
常用的filters功能:
- grok - 功能强大文本处理插件,主要用于格式化文本内容。
- drop - 丢弃一些数据
outputs
Logstatsh的最后一个处理节点,outputs负责将数据同步到目的地。
下面是常见的目的地:
- elasticsearch
- file - 也可以将数据同步到一个文件中
Codecs
codecs就是编码器,负责对数据进行序列号处理,主要就是json和文本两种编码器。